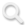(49)
(49)
 (0)
(0)
 收藏
收藏
在最新人工智能(AI)技术的加持下,达芬奇名作中的蒙娜丽莎不只是淡淡微笑,还可以眉飞色舞地唱起RAP。
近日,微软推出最新AI模型VASA-1,新技术的亮点是可将人的静态图像和语音音频片段生成逼真的视频。
之前OpenAI推出的Sora是“文生视频”,VASA-1可以说是“图生视频”。
按照微软的说法,VASA-1生成的视频可以做到人物口型与音频完美同步,还能展现丰富的面部表情和自然的头部动作,使整个视频显得既真实又充满活力。
VASA-1不仅能对真人图像或照片施展“魔法”,还能让静态的卡通人物或艺术作品中的人物开口说话、唱歌。
比如达芬奇名画《蒙娜丽莎》可以“演绎”RAP说唱。
在微软演示的这段视频中,蒙娜丽莎秒变活力四射的歌手,唱起了安妮·海瑟薇在一档脱口秀节目中创作和表演的说唱歌曲。
微软研究人员表示,他们用大量人类说话时的面部表情视频训练新AI模型,包括口型变化、面部表情、目光凝视和眨眼等,使得生成的视频栩栩如生。此外,新模型还能控制或设定人物的视线方向或特定表情。
不过,VASA-1的“图生视频”被认为仍然留有机器生成的痕迹。例如,眨眼还不够频繁自然,眉毛动作也略显夸张。
研究人员承认,该模型和其他AI模型一样,在处理头发等元素方面仍有困难。
但微软方面称,VASA-1仍优于其他类似模型,为AI数字人未来能更像真人一样与人实时互动铺平道路。
在应用领域,VASA-1还能为有沟通障碍者提供支持,甚至有望为人类创造虚拟伴侣。
社交媒体上,不少网友对微软新AI模型生成的视频逼真度感到惊讶,形容其“真实得可怕”。还有评论说,“太疯狂、太怪异、太恐怖了”。
微软表示,这一最新AI模型确实存在被滥用的风险,比如用来冒充真人进行欺诈或传播虚假信息。
为此,微软迄今尚未公开发布VASA-1。研究人员说,需要确定这项技术能按照适当的规定被负责任地使用时才会发布。
(视频素材来自社交媒体X等。编辑邮箱:ylq@jfdaily.com)
 我也说两句
我也说两句



































































 沪公网安备 31010602000361号
沪公网安备 31010602000361号